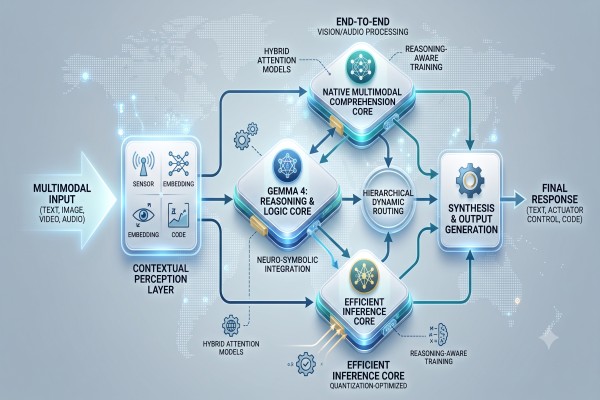
Figure 1: Theoretical Gemma 4 Architectural Schema
The image below illustrates the conceptual workflow for Gemma 4, prioritizing specialized neural clusters linked via dynamic routing.
(Figure 1: Architectural diagram detailing the theoretical multi-core structure of Gemma 4, featuring specialized clusters for Reasoning, Efficiency, and Multimodality, linked by a dynamic routing layer.)
Gemma 4 is not simply about an arbitrary version increment; it represents the next generation of the specialized “Gemma architecture.” If Gemma 2 was the refinement of efficiency, Gemma 4 must be the architect of comprehensive reasoning and multimodal mastery.
Here, we explore the theoretical breakthrough technologies, the paradigm shift in architectural design, and the specialized ecosystem required to build Gemma 4.
Beyond Transformers: The Neural-Symbolic Shift
The current dominant paradigm, the Transformer architecture, has powered the AI boom. Gemma 4, however, arrives at a moment where pure Transformers may hit diminishing returns regarding deep, logical reasoning.
To achieve true breakthrough status, Gemma 4 needs to move beyond simple pattern matching and statistical next-token prediction. It must embrace Neuro-Symbolic AI.
Neuro-Symbolic AI aims to integrate the strengths of deep learning (pattern recognition, intuition, and perception, which neural networks excel at) with symbolic AI (logical reasoning, rule processing, and knowledge representation). This hybrid approach is the critical key to unlocking reliable mathematical problem solving, rigorous scientific deduction, and hallucination-resistant fact retrieval—areas where even the best current LLMs struggle.
The Specialized Core: Three Pillars of Gemma 4
A theoretical Gemma 4 architecture would not be a single monolithic model. It would be designed as a tightly integrated system of specialized neural cores.
-
The Deep Reasoning Core (Neural-Symbolic): This is the engine of logical thought. Moving away from standard attention mechanisms, this core might employ a specialized “Deduction Layer” that actively constructs formal logical proofs or utilizes knowledge graphs during inference. This would allow the model to trace why an answer is correct, rather than just asserting it is. This core would handle planning, code generation, and complex math.
-
The Efficient Perceptual Core: This is the evolution of the lightweight Gemma model. It is optimized for extremely fast inference and low memory footprint (think Gemma 2B or 7B). Its primary role is quickly synthesizing context, managing conversation flow, and handling rapid data processing on edge devices.
-
The Native Multimodal Core: True multimodal capability is no longer an “add-on” via cross-attention. For Gemma 4, image, audio, and video comprehension must be inherent to the architecture, trained end-to-end. This means the model processes pixels, waveforms, and text embeddings simultaneously, allowing it to “understand” a video tutorial by synthesizing visual data with the audio explanation, not just transcribing it.
The Architectural Blueprint: Dynamic and Fluid
The physical manifestation of this specialized approach requires an innovative underlying structure. Gemma 4’s architecture must be dynamic.
The current trend toward MoE (Mixture-of-Experts) models, as seen in systems like Mixtral, is a precursor to the fully dynamic routing Gemma 4 needs. But rather than simple expert switching based on token type, Gemma 4 requires Hierarchical Dynamic Routing.
A theoretical blueprint for Gemma 4 (referencing Figure 1) visualizes how a user prompt is first routed by a “Task Classifier/Planner” layer. This layer identifies the cognitive load required:
-
Routine tasks (e.g., summarizing a paragraph) are immediately routed to the Efficient Perceptual Core.
-
Logical or scientific queries (e.g., proving a geometry theorem) are routed to the Deep Reasoning Core, which might activate a symbolic deduction engine.
-
Multimodal queries (e.g., analyzing a video file) are simultaneously fed into specialized image/audio modules before synthesis.
This creates a “Fluid Intelligence” system where model size effectively scales in real-time, engaging specialized sub-architectures only when needed. This approach drastically improves efficiency during inference compared to standard dense models.
Reasoning-Aware Training and Safety-by-Design
Building the model structure is only half the battle. Gemma 4 must be trained differently.
1. Reasoning-Aware Pre-training
Standard pre-training focuses on maximizing the likelihood of the next word. Gemma 4 requires pre-training data that prioritizes the chain of thought. Instead of feeding the model millions of web pages, training data must be curated with high-quality, step-by-step reasoning processes, scientific derivations, and logical proofs.
2. Built-in Safety Verifiers
Safety cannot be an afterthought solved only via Reinforcement Learning from Human Feedback (RLHF) after training. Gemma 4 must integrate safety directly into its neural structure. This means developing “Safety Experts” within the specialized MoE architecture. These experts are specifically trained to identify, flag, and neutralize harmful or biased content before the output synthesis stage.
The Open-Weights Ecosystem
Finally, the success of Gemma 4 will be measured not just by its benchmarks, but by its impact on the open ecosystem. To support dynamic, fluid architectures, new toolchains are required:
-
Dynamic Inference Servers: Software that understands how to load and hot-swap different modules/cores of Gemma 4 dynamically on local hardware or distributed cloud systems.
-
Specialized Quantization: As the models specialize, quantization techniques (e.g., 4-bit and 2-bit weight compression) must be tailored to protect the critical attention pathways of the Deep Reasoning Core.
-
Modular Fine-Tuning: Users should be able to fine-tune only the Efficient Perceptual Core for small device tasks, or only the Deep Reasoning Core for specialized scientific domains, without modifying the whole architecture.
Gemma 4 must define the roadmap for specialized, reasoning-capable, open AI. It’s a blueprint that moves beyond “bigger is better,” arguing instead that “specialized is smarter.“